递归底漆使用C:第3部分
 1。简介
1。简介
在这篇文章[3] [4部分,我们讨论递归从不同的维度。在thenbsp;第一部分中,我们讨论了我们如何可以实现在运行时和编译时的五个不同类型的递归。在第二篇文章中,我们讨论了从另一个层面,即生成的递归和递归结构相同的五个不同类型的递归。在这篇文章中,我们尝试结合在一起的尺寸,即编译时/运行和结构/生成五个不同类型的递归。2。递归类型2.1。递归方式执行的基础上
在C语言中,递归的类型,可以在多个维度定义。在一维的,它可以被归类为运行时间的递归和编译时递归使用模板元编程。运行时间递归递归是最常见的技术,用于在C。这可以实现C函数(或成员函数)调用自身。2.2。参数和解决问题的基础上的递归方式
递归也可以分为结构递归和生成递归。之间thesenbsp的主要区别是,通常生成递归分解成子问题,原来的问题,并解决它。例如,要计算给定数的阶乘,我们计算阶乘的一个数字比给定的数字少,并继续这样做,直到我们达到终止条件。在二进制搜索的情况下,我们分为2件给定的数组和运行的二进制搜索。在这种情况下,我们消除了一半的元素,在每一个递归调用,直到我们找到所需的元素,或者达到一个地步,我们只有一个元素左。现在,如果该元素是必需的,然后我们发现后的log2(N)的比较(即最坏的情况下),其中"n是一个数组中的元素的总数??
另一方面,结构递归通常执行的问题分解成小块,而不是数据。我们可以存储如二进制树的递归结构的数据,在这种情况下,使用递归来执行它的操作很自然。结构递归不仅限于递归数据结构,但它会在一些线性结构,如链接列表非常方便。2.3。递归算法的基础上类型
看到递归的另一种方法是递归算法是如何实现的。递归算法可以实现在一个以上的方法,如线性,尾巴,相互的,二进制或嵌套递归。
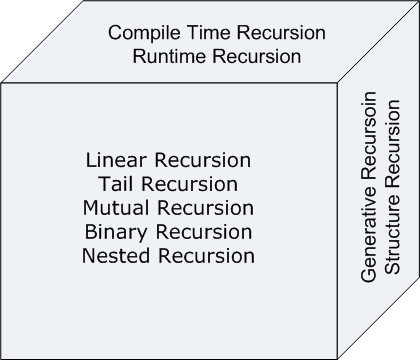
在这篇文章中,我们要学习尊重所有维度的递归类型。这意味着我们要研究20个不同类型的递归。另外请注意,我们甚至不包括我们在文章的第1部分中讨论的模板递归。我们可以用这个简单的框图显示的递归类型这三个层面:{S0}
因为这是递归的三个维类型,我们不能仅仅代表一个表。一个可能的表表示修复一个表中的一类递归,并显示所有其他的可能性。一个可能的分解是分解成编译时和运行时。这是相当合乎逻辑的打破,因为编译的时候递归并不是在所有的编程语言的可能。如果有人正在使用C以外,编译时表中可以忽略不计。
下面是一个表来表示不同类型的运行时间递归算法。{S1}
同样,这里是一个表来表示不同类型的编译时间递归算法。这些类型的递归算法是非常具体到C,因为不是每个语言支持编译时递归或模板元编程。{S2}
此图显示了20个不同类型的算法块的形式详细一点。 3。线性递归
3。线性递归
线性递归递归的最简单的形式,也许是最常用的递归。在此递归,一个功能简单地调用自身,直到达到终止条件(又称基本条件);这个过程称为绕组。调用终止条件后,执行方案返回给调用者,这是作为平仓。3.1。运行时结构的线性递归
单链接列表也许是最常用的和实现简单线性递归数据结构。我们可以实现链接列表算法的迭代或递归。下面是简单的印刷单链接列表的所有元素递归递归实现。//<span class="code-comment"> Node for Single Link List
</span>struct Node
{
int value;
Node* next;
};
//<span class="code-comment"> Singly Link List Traversal using Linear Recursion
</span>//<span class="code-comment"> Structure Linear Recursion
</span>void PrintNode(Node* pHead)
{
if (pHead != NULL)
{
PrintNode(pHead->next);
std::cout << pHead->value << std::endl;
}
else return;
}
我们可以执行编译时版本的链接列表与模板元编程的帮助。下面是一个简单的代码来创建一个编译时单链接列表的节点:{C}
在这里,我们需要的第一个空结构终止递归和使用它作为一个基类。这个空结构的目的是引入一个类型,什么也不做,并用这个模板特殊化或终止编译时递归模板偏特化。下面是一个编译时单链接列表的例子。typedef Node<15, Node<20, Node<35, End> > > staticList;
在编译时的世界,我们不能执行循环。只有这样,才能模拟它是通过使用编译的时间递归。这里有几个算法在编译时单链路使用编译时间递归列表。//<span class="code-comment"> Structure to calculate the length of Static Link List
</span>template <typename T>
struct Length;
//<span class="code-comment"> Partial Template Specialization call recursively calculate the length
</span>template <int iData, typename Type>
struct Length<Node<iData, Type> >
{
enum { value = Length<Type>::value + 1 };
};
//<span class="code-comment"> Template Specialization to terminate recursion
</span>template <> struct Length<End>
{
enum { value = 0 };
};
//<span class="code-comment"> Structure to add the items in Static Link List
</span>template <typename T>
struct Add;
//<span class="code-comment"> Partial Template Specialization call recursively to add items
</span>template <int iData, typename Type>
struct Add<Node<iData, Type> >
{
enum { value = Add<Type>::value + iData };
};
//<span class="code-comment"> Template Specialization to terminate recursion
</span>template <>
struct Add<End>
{
enum { value = 0 };
};
//<span class="code-comment"> Structure to multiply the items in Static Link List
</span>template <typename T>
struct Multiply;
//<span class="code-comment"> Partial Template Specialization call recursively to multiply items
</span>template <int iData, typename Type>
struct Multiply<Node<iData, Type> >
{
enum { value = Multiply<Type>::value * iData};
};
//<span class="code-comment"> Template Specialization to terminate recursion
</span>template <> struct Multiply<End>
{
enum { value = 1 };
};
这里是它的用法:std::cout << Length<staticList>::value << std::endl;
std::cout << Add<staticList>::value << std::endl;
std::cout << Multiply<staticList>::value << std::endl;
如果我们都应该做一个功能,将创建和填充一个向量(或任何其他数据结构)与一些预定义的数据,那么我们可以解决这个循环或使用递归。下面是该函数的递归版本:bool makeVector(std::vector<int>& vec, int low, int high, int increment = 1)
{
if (low > high)
return false;
if (low == high)
return true;
else
{
vec.push_back(low); makeVector(vec, low+increment, high, increment);
}
return true;
}
在这个函数中,我们在载体中插入低的值,然后增加它,然后调用递归,直到低价值大于价值较高的。下面是这个函数的用法:std::vector<int> vec;
makeVector(vec, -5, 10, 2);
std::copy(vec.begin(), vec.end(), std::ostream_iterator<int>(std::cout, "\n"));
也许最简单,最有名的例子生成线性递归计算阶乘。计算阶乘的同时,我们不断地分成子问题的问题。下面是一个编译时生成的线性递归的例子。template <int No> struct Factorial
{
//<span class="code-comment"> linear recursive call
</span> enum { value = No * Factorial<No - 1>::value };
};
//<span class="code-comment"> termination condition
</span>template <> struct Factorial<0>
{
enum { value = 1 };
};
下面是这种用法:
让我们看看约瑟夫问题的讨论在混凝土中的数学[2]的变化。
"犹太罗马战争期间,他[约瑟夫]是由罗马人被困在山洞里的41个犹太叛乱分子之间的一个乐队。宁愿自杀捕捉到,叛军决定形成一个圆圈,它周围出发,杀死每三余人,直到没有人离开.???[ 2]
"在我们的变化,我们开始与N多人编号为1至"N?围绕一个圆?,和我们消除每秒其余的人,直到只有一个生存??[2]。
下面是解决这个问题的数学公式: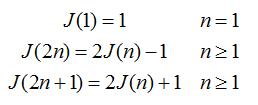 的
的
这里是thenbsp;编译时生成班轮的递归函数来解决这个问题:
这里是它的用法:std::cout << JosephusProblem<5>::value << std::endl;
std::cout << JosephusProblem<8>::value << std::endl;
std::cout << JosephusProblem<4>::value << std::endl;
尾递归是一种特殊形式的线性递归递归函数调用通常是最后一次通话的功能。这种类型的递归通常更有效,因为聪明的编译器会自动转换成循环,以避免嵌套的函数调用这个递归。由于递归函数调用通常是一个函数的最后一个语句,没有做任何工作,而不是在平仓阶段,他们简单的返回值递归函数调用。换言之,递归函数不存储任何状态信息,并在平仓阶段,只是返回值。4.1。运行时结构的尾递归
让我们再看看在单链接列表的例子。如果我们想找到的链接列表中的最大值,我们可以做它用或循环或递归。下面是一个例子,发现使用尾递归中的链接列表的最大价值://<span class="code-comment"> Node for Single Link List
</span>struct Node
{
int value;
Node* next;
};
void AddItem(Node** pHead, int iData)
{
if (*pHead == NULL)
{
(*pHead) = new Node();
(*pHead)->value = iData;
(*pHead)->next = NULL;
}
else
{
Node* pTemp = *pHead;
while (pTemp->next != NULL)
{
pTemp = pTemp->next;
}
Node* newNode = new Node();
newNode->value = iData;
newNode->next = NULL;
pTemp->next = newNode;
}
}
//<span class="code-comment"> Find the maximum value of link list using Tail Recursion
</span>int maxValue(Node* pHead, int MaxValue)
{
if (pHead->next == NULL)
return MaxValue;
else
return maxValue(pHead->next, pHead->value >
MaxValue ? pHead->value : MaxValue);
}
下面是这个函数的简单用法:Node* pHead = NULL;
AddItem(&pHead, 8);
AddItem(&pHead, 20);
AddItem(&pHead, 12);
AddItem(&pHead, 22);
AddItem(&pHead, 5);
std::cout << maxValue(pHead, 0) << std::endl;
我们可以在编译时做同样的事情。在这里我们首先要定义一些结构来创建一个编译时链接列表。下面是一个简单的代码来创建一个编译时单链接列表的节点:{C}
现在,我们要添加的链接列表中的所有元素的所有值。在编译时,唯一的方法来遍历链接列表是使用递归,但在这里我们使用的是尾递归遍历链接列表,并添加所有数据项的值。//<span class="code-comment"> Structure to add the items in Static Link List
</span>template <typename T>
struct Add;
//<span class="code-comment"> Partial Template Specialization call recursively to add items
</span>template <int iData, typename Type>
struct Add<Node<iData, Type> >
{
enum { value = iData + Add<Type>::value };
};
//<span class="code-comment"> Template Specialization to terminate recursion
</span>template <>
struct Add<End>
{
enum { value = 0 };
};
下面是一个简单的用法:typedef Node<15, Node<20, Node<35, End> > > staticList;
std::cout << Add<staticList>::value << std::endl;
如果我们要扭转的数量,然后再我们可以用不同的方式执行它。下面是简单尾递归版本://<span class="code-comment"> Reverse the given number using Tail Recursion
</span>int reverseNumber(int n, int r = 0)
{
if (n == 0)
return r;
else
return reverseNumber(n/10, (r*10)+(n%10));
}
这个函数调用本身一次又一次的递归和传递输入参数后除以10,直到它等于0。同时,这个函数创建一个反向号码,16是通过第二个参数作为其自身的平仓阶段,它只是返回的数量,因为它是。这里是它的简单用法。std::cout << reverseNumber(2468) << std::endl;
std::cout << reverseNumber(-1357) << std::endl;
这是一个线性递归程序的修改后的版本。在这里,我们调用递归函数之前执行所有的计算,和简单的返回值,我们从递归函数得到。template <int No, int a>
struct Factorial
{
//<span class="code-comment"> tail recursive call
</span> enum { value = Factorial<No - 1, No * a>::value };
};
//<span class="code-comment"> termination condition
</span>template <int a>
struct Factorial<0, a>
{
enum { value = a };
};
下面是这个简单的用法:std::cout << Factorial<6, 1>::value << std::endl;
相互递归也称为间接递归。在这种类型的递归函数调用,两个或两个以上彼此在一个圆形的方式。这是唯一的方法做,如果编程语言不允许递归调用函数的递归。此递归的终止条件,可以在一个或所有功能。5.1。运行时结构相互递归
让我们来看看问题,检查给定的字符串是否是回文或。回文字符串是一个字符串,它可以thenbsp;同无论从向左或向右读,如"汉娜?? "的宗旨? "公民"?和"女士??根据定义,一个字母的单词也是一个回文,因此这个函数返回true,如果给定的字符串的长度只有一个。此函数调用另一个名为辅助功能??代码> helperPlaindrome??这是检查的第一个和最后一个字母的字符串,并调用isPlaindrome。
下面是检查字符串是回文或不使用相互递归的简单实现:bool isPlaindrome(const std::string& str);
bool helperPlaindrome(const std::string& str);
bool isPlaindrome(const std::string& str)
{
//<span class="code-comment"> base condition
</span> if (1 == str.length())
return true;
//<span class="code-comment"> Call the helper function
</span> return helperPlaindrome(str);
}
bool helperPlaindrome(const std::string& str)
{
//<span class="code-comment"> call function isPlandrome
</span> //<span class="code-comment"> after checking first and last character in string
</span> if (str.length())
return str.at(0) == str.at(str.length() - 1)
&& isPlaindrome(str.substr(1, str.length() - 2));
else return true;
}
下面是一个简单的使用这个功能:std::cout << isPlaindrome("MADAM") << std::endl;
我们再次创建编译时链接列表写结构相互递归函数。这种方法是非常类似的编译时间结构线索递归函数。唯一不同的是,现在我们正在创建两个函数(在编译时的世界结构)彼此相互调用。我们有一个函数(在这种情况下结构)内部调用ADD2,同样ADD2内部调用ADD1,直到其中任何一个到达的链接列表的名称地址1。下面是一个简单的实现这两个相互递归函数(构)筑物://<span class="code-comment"> Structure to add the items in Static Link List
</span>template <typename T>
struct Add1;
//<span class="code-comment"> Structure to add the items in Static Link List
</span>template <typename T>
struct Add2;
//<span class="code-comment"> Partial Template Specialization call recursively Add2 to add items
</span>template <int iData, typename Type>
struct Add1<Node<iData, Type> >
{
enum { value = Add2<Type>::value + iData };
};
//<span class="code-comment"> Template Specialization to terminate recursion
</span>template <> struct Add1<End>
{
enum { value = 0 };
};
//<span class="code-comment"> Partial Template Specialization call recursively Add1 to add items
</span>template <int iData, typename Type>
struct Add2<Node<iData, Type> >
{
enum { value = Add1<Type>::value + iData };
};
//<span class="code-comment"> Template Specialization to terminate recursion
</span>template <> struct Add2<End>
{
enum { value = 0 };
};
下面是一个简单的使用这些功能:typedef Node<15, Node<20, Node<35, End> > > staticList;
std::cout << Add1<staticList>::value << std::endl;
有一些有趣的相互递归问题讨论[1]。我们已经知道了Fibonacci数。被定义为一对兔Fibonacci数的实际问题,我们都应该计算"N??个月后的兔子总数。这些问题中定义的条件。
在第一个月中,只有一对或兔子,想他们需要一个月产生一个对婴儿和永远不死。此外,他们总是生产的一雄一雌兔对。如果再算上在每月的总对数,然后这些都是斐波纳契数字。
这里是数学公式来计算成人和婴儿兔[1]:{五}{中六}
这是一个相互递归的情况下,因为婴儿的功能是调用成人功能和成人的函数调用婴儿函数。下面是简单的程序来实现这些:int BabyPair(int no);
int AdultPair(int no);
int BabyPair(int no)
{
if (no == 1)
return 1;
else
return AdultPair(no - 1);
}
int AdultPair(int no)
{
if (no == 1)
return 0;
else
return AdultPair(no - 1) + BabyPair(no - 1);
}
下面是一个简单的使用这些功能:std::cout << "Adult Pair at 10th generation: " << AdultPair(10) << std::endl;
std::cout << "Baby Pair at 10th generation: " << BabyPair(10) << std::endl;
让我们看看在相互递归的另一个例子。这就是所谓的男序列和女序列。下面是对这些数学公式。{七}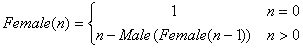
下面是这个生成的相互递归的编译时实施:template <int n> struct MaleSequence
{
//<span class="code-comment"> mutually recursive call
</span> enum { value = n - FemaleSequence<MaleSequence<n - 1>::value>::value };
};
//<span class="code-comment"> termination condition
</span>template <> struct MaleSequence<0>
{
enum { value = 0 };
};
template <int n> struct FemaleSequence
{
//<span class="code-comment"> mutually recursive call
</span> enum { value = n - MaleSequence<FemaleSequence<n - 1>::value>::value };
};
//<span class="code-comment"> termination condition
</span>template <> struct FemaleSequence<0> {
enum { value = 1 };
};
下面是这个简单的用法:std::cout << FemaleSequence<6>::value << std::endl;
std::cout << MaleSequence<6>::value << std::endl;
在二进制递归,递归函数调用了两次,一次也没有。这种类型的递归是非常有用的,就像穿越一个前缀,后缀或中缀为了树的一些数据结构,生成Fibonacci数等
二进制递归指数递归的一种具体形式,其中一个函数调用递归函数不止一次(两个二进制的情况下)。换言之,递归函数调用指数在这种类型的递归。6.1。运行时结构的二进制递归
二叉树是一个典型的例子二元递归。在二叉树中,每个节点有两个子节点,每个子节点可能包含两个孩子。递归是一种自然的选择在这里,因为数据结构的递归性质。下面是简单的代码,在二叉树中添加项目。//<span class="code-comment"> Node for Binary Tree
</span>struct TreeNode
{
int iData;
TreeNode* pLeft;
TreeNode* pRight;
};
//<span class="code-comment"> Add Items in Binary Tree
</span>void AddItem(TreeNode** pRoot, int iData)
{
if (*pRoot == NULL)
{
(*pRoot) = new TreeNode();
(*pRoot)->iData = iData;
(*pRoot)->pLeft = NULL;
(*pRoot)->pRight = NULL;
}
else
{
if (iData < (*pRoot)->iData)
AddItem(&(*pRoot)->pLeft, iData);
else if (iData > (*pRoot)->iData)
AddItem(&(*pRoot)->pRight, iData);
}
}
下面是一个简单的二进制打印二叉树的递归实现。我们注意每个递归调用,调用同一个函数超过一次,两次,在这种情况下(因为它是二进制递归)。如果我们调用同一个函数的两倍以上,那么它被称为指数递归。//<span class="code-comment"> Traversing Binary Tree
</span>//<span class="code-comment"> Structure Binary Recursion
</span>void PrintTree(TreeNode* pRoot)
{
if (pRoot == NULL)
return;
PrintTree(pRoot->pLeft);
std::cout << pRoot->iData << std::endl;
PrintTree(pRoot->pRight);
}
这里是它的一个简单的用法:TreeNode* pRoot = NULL;
AddItem(&pRoot, 10);
AddItem(&pRoot, 20);
AddItem(&pRoot, 15);
AddItem(&pRoot, 12);
AddItem(&pRoot, 27);
AddItem(&pRoot, 8);
PrintTree(pRoot);
就像运行时版本,我们可以创建一个在编译时二叉树。这里是一个简单的节点的例子来创建二叉树。这和编译时链接列表之间的主要区别是在这里我们有左,右节点的typedef(相当于在运行时版本参考)。//<span class="code-comment"> Node of Static Tree
</span>template <int iData, typename Left, typename Right>
struct Node
{
enum { value = iData };
typedef Left left;
typedef Right right;
};
编译时这个简单的二元结构的递归函数增加了树中的所有值。注意,这里我们调用同一个函数(这里实例化结构),两次遍历二叉树的左,右侧。//<span class="code-comment"> Structure to add the items in Static Tree
</span>template <typename T>
struct Add;
//<span class="code-comment"> Partial Template Specialization call recursively to add items values
</span>//<span class="code-comment"> Use recursion twice to traverse the tree
</span>template <int iData, typename Left, typename Right>
struct Add<Node<iData, Left, Right> >
{
enum { value = Add<Left>::value + Add<Right>::value + iData };
};
//<span class="code-comment"> Template Specialization to terminate recursion
</span>template <>
struct Add<End>
{
enum { value = 0 };
};
让我们做更多的东西,而不仅仅是增加的值。让我们尝试计算二叉树的高度,假设它是二叉搜索树。要做到这一点,我们需要一些比较辅助功能(结构在这里)。下面是我们的helper结构://<span class="code-comment"> Find the maximum number
</span>template <int u, int v>
struct Maximum
{
enum { value = u > v ? u : v };
};
//<span class="code-comment"> Find the minimum number
</span>template <int u, int v>
struct Minimum
{
enum { value = u < v ? u : v };
};
现在让我们来实现高度的方法。随着助手结构的帮助下,这是很容易实现的,这也是一个编译时间结构的二进制递归的例子。template <typename T>
struct Height;
template <int iData, typename Left, typename Right>
struct Height<Node<iData, Left, Right> >
{
enum { value = Maximum<Height<Left>::value + 1,
Height<Right>::value + 1>::value };
};
这里是它的一个简单的用法。注意:在这里,我们首先创建一个二进制搜索树自己,因为这个编译时树已十分有限的功能,并没有为我们做这。typedef Node<100,
Node<50, Node<10, End, End>, Node<75, End, End> >,
Node<150, Node<125, End, End>, Node<175, End, End> > > tree1;
typedef Node<100,
Node<50,
Node<10,
Node<60, End, End>,
Node<3,
Node<12, End, End>,
End> >,
Node<75,
End,
Node<5, End, End> > >,
Node<5, End, End> > tree2;
std::cout << Add<tree1>::value << std::endl;
std::cout << Height<tree1>::value << std::endl;
std::cout << Add<tree2>::value << std::endl;
std::cout << Height<tree2>::value << std::endl;
在合并排序,我们细分两件我们的数组(或载体),并继续这样做,直到有留在子数组只有一个元素,然后我们合并所有的子阵列。这一方案的分裂一块是相当简单,真正有趣的部分是在mergeVectors功能。我们可以实现在两个方面mergeVectors功能。要么我们可以创建一个新的临时载体和插入元素,或者我们只是交换现有载体的价值。在这个程序中,我们使用第二种方法,即现有载体的交换价值,而不是创建一个新的。//<span class="code-comment"> Function to merge two lists
</span>//<span class="code-comment"> In this function we are just swapping the values of two vectors
</span>//<span class="code-comment"> using nested loop, without creating any new temporary vector
</span>void mergeVectors(std::vector<int>::iterator iStart,
std::vector<int>::iterator iMid, std::vector<int>::iterator iEnd)
{
//<span class="code-comment"> Traverse through the first list
</span> for (std::vector<int>::iterator iter_ = iStart; iter_ != iMid; ++iter_)
{
//<span class="code-comment"> if Current element of First list
</span> //<span class="code-comment"> is greater than first element of second list
</span> //<span class="code-comment"> We do not check elements in the first list
</span> //<span class="code-comment"> because both list should already sorted
</span> if (*iter_ > *iMid)
{
//<span class="code-comment"> Store the current value in temporary variable
</span> int iTemp = *iter_;
*iter_ = *iMid;
//<span class="code-comment"> Store the first position in temporary location
</span> std::vector<int>::iterator iTempIter = iMid;
//<span class="code-comment"> Move the all the elements of the list to left
</span> //<span class="code-comment"> which are greater than current value
</span> //<span class="code-comment"> to make room for current value to insert at the
</span> //<span class="code-comment"> first place of second list
</span> while (iTempIter + 1 != iEnd && *(iTempIter + 1) < iTemp)
{
std::swap(*iTempIter, *(iTempIter + 1));
++iTempIter;
}
//<span class="code-comment"> Now we have moved all the elements to the next place
</span> //<span class="code-comment"> therefore we can copy the current element
</span> *iTempIter = iTemp;
}
}
}
//<span class="code-comment"> Recursive function call itself recursively
</span>void mergeSort(std::vector<int>::iterator iStart, std::vector<int>::iterator iEnd)
{
size_t iSize = iEnd - iStart;
if (iSize <= 1)
return;
std::vector<int>::iterator iMid = iStart + (iSize / 2);
//<span class="code-comment"> Call itself twice example of Binary Recursion
</span> mergeSort(iStart, iMid);
mergeSort(iMid, iEnd);
mergeVectors(iStart, iMid, iEnd);
}
下面是一个简单的使用这个功能:mergeSort(vec.begin(), vec.end());
Fibonacci数也许是最简单的实现生成的二进制递归。 thenbsp;最简单的实现,在计算任何Fibonacci数,前两个以外,我们首先要计算最后两个斐波纳契数字。下面是这个简单的执行。template <int n> struct Fib
{
//<span class="code-comment"> binary recursive call
</span> enum { value = Fib<n - 1>::value + Fib<n - 2>::value };
};
//<span class="code-comment"> termination condition
</span>template<> struct Fib<2>
{
enum { value = 1 };
};
//<span class="code-comment"> termination condition
</span>template <> struct Fib<1>
{
enum { value = 1 };
};
下面是一个简单的使用这个功能:std::cout << Fib<16>::value << std::endl;
这是一个递归嵌套递归调用时的特殊类型。所有上述递归我们可以替换是简单的循环或循环与堆栈,但这种类型的递归不能轻易取代简单的循环。在这种类型的递归,每一个递归函数调用另一个函数,这也是一个递归函数。嵌套递归函数可以是函数本身,也可以完全是另一种功能。7.1。运行时结构嵌套递归
嵌套链接列表,可以是一个结构化嵌套递归很好的例子。在简单的链接列表,链接列表中的每个节点只包含数据,以及下一个节点的地址。在嵌套链接列表的情况下,一个链接列表中的每个节点包含两个地址。第一个地址是一样简单的链接列表中包含的链接列表中的下一个节点的地址,但在第二个节点是多了一个链接列表的地址。
换句话说,每个节点可以包含一个链接列表的地址。现在的问题是什么,可能是这样一个复杂的数据结构的优势,当我们可以用二维阵列同样的事情吗?二维数组的主要问题是,每一个维度应该有相同的长度,就像矩阵。我们不能使每行含有不同数量的元素的二维数组。
在这里,我们有两种不同类型的节点。节点是相同的,因为我们早在简单的链接列表的情况下研究。 NestedNode有两个指针,一个存储同一类型的下一个节点的地址NestedNode类型,另一种是存储的嵌套链接列表头地址创建一个链接列表。
下面是一个简单的例子,这两种类型的节点和嵌套的递归实现显示嵌套链接列表的值。在这里,我们递归的TraverseNode方法,该方法内部调用PrintNestedList的方法,这也是一个递归函数。 TraverseNode打印外的链接列表和PrintNestedList,作为thenbsp;顾名思义,嵌套链接列表打印值。//<span class="code-comment"> Node for Inner Link List
</span>struct Node
{
int iData;
Node* pNextNode;
Node()
{
iData = 0;
pNextNode = NULL;
}
};
//<span class="code-comment"> Node for Nested Link List
</span>struct NestedNode
{
int iData;
Node* pHead;
NestedNode* pNextList;
NestedNode()
{
iData = 0;
pHead = NULL;
pNextList = NULL;
}
};
//<span class="code-comment"> Print the inner link list
</span>void PrintNestedList(Node* pHead)
{
if (pHead != NULL)
{
std::cout << " -> " << pHead->iData << std::endl;
PrintNestedList(pHead->pNextNode);
}
else
return;
}
//<span class="code-comment"> Print the outer link list
</span>void TraverseNode(NestedNode* pHead)
{
if (pHead == NULL)
return;
else
{
std::cout << pHead->iData << std::endl;
PrintNestedList(pHead->pHead);
TraverseNode(pHead->pNextList);
}
}
下面是一个简单的使用这个功能://<span class="code-comment"> Traverse Nested Link Recursively
</span>//<span class="code-comment"> Every items itself is Link List
</span>//<span class="code-comment"> Traverse that Link List Recursively too
</span>//<span class="code-comment"> to print all items in Nested Link List
</span>//<span class="code-comment"> Recursive function call another recursive function
</span>TraverseNode(pNested);
用类似的方法,我们可以在编译时创建一个嵌套的链接列表。在这里,我们定义了两个节点类型,就像运行时版本。此外,我们来定义两个不同的结束标记,链接列表和嵌套链接列表的末尾,并NestedEnd分别。//<span class="code-comment"> Termination of Link List
</span>struct End
{
};
//<span class="code-comment"> Node of Static Link List
</span>template <int iData, typename Type>
struct Node
{
enum { value = iData };
typedef Type Next;
};
//<span class="code-comment"> Termination of Nested Link List
</span>struct NestedEnd
{
};
//<span class="code-comment"> Node of Nested Link List
</span>template <int iData, typename NestedType, typename Type>
struct NestedNode
{
enum { value = iData };
typedef NestedType NestedList;
typedef Type Next;
};
,而不是印刷嵌套的链接列表的值在这里我们要算在链接列表和嵌套链接列表的值。这里计数是一个结构递归实例本身以及结构长度。结构长度也实例计算嵌套链接列表的长度。//<span class="code-comment"> Structure to calculate the length of Static Link List
</span>template <typename T>
struct Length;
//<span class="code-comment"> Partial Template Specialization call recursively calculate the length
</span>template <int iData, typename Type>
struct Length<Node<iData, Type> >
{
enum { value = 1 + Length<Type>::value };
};
//<span class="code-comment"> Template Specialization to terminate recursion
</span>template <> struct Length<End>
{
enum { value = 0 };
};
//<span class="code-comment"> Structure to calculate the number of elements in Nested Static Link List
</span>template <typename T>
struct Count;
//<span class="code-comment"> Partial Template Specialization call recursively calculate the length
</span>template <int iData, typename NestedType, typename Type>
struct Count<NestedNode<iData, NestedType, Type> >
{
enum { value = 1 + Count<Type>::value + Length<NestedType>::value };
};
template <>
struct Count<NestedEnd>
{
enum { value = 0 };
};
下面是一个简单的使用这些结构:7.3。运行时生成的嵌套递归
麦卡锡功能,又称麦卡锡91功能是嵌套的递归函数由约翰麦卡锡定义。此功能是作为正式核查系统的测试情况下提出的。这也被称为麦卡锡91功能,因为每个值小于100,这个函数返回91。
下面是这个函数的数学公式:
下面是简单的实现这个功能://<span class="code-comment"> Generative Nested Recursion
</span>int McCarthy(int no)
{
if (no > 100)
return no - 10;
else
return McCarthy(McCarthy(no + 11));
}
下面是简单的使用这个功能:std::cout << McCarthy(25) << std::endl;
嵌套递归函数的例子是阿克曼函数。爆炸此功能非常迅速,因此,它通常用于检查编译器的能力,优化递归。这里是阿克曼函数的数学公式: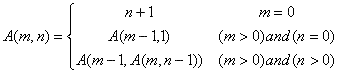
这是简单的编译此嵌套函数的执行时间:template <int m, int n>
struct Ackermann
{
//<span class="code-comment"> nested recursive call
</span> enum { value = Ackermann<m-1, Ackermann<m, n-1>::value>::value };
};
template <int m> struct Ackermann<m, 0>
{
//<span class="code-comment"> linear recursive call
</span> enum { value = Ackermann<m-1, 1>::value };
};
//<span class="code-comment"> termination condition
</span>template <int n>
struct Ackermann<0, n>
{
enum { value = n + 1 };
};
下面是一个使用此功能:std::cout << Ackermann<2, 3>::value << std::endl;
曼努埃尔卢比奥桑切斯,海梅Urquiza富恩特斯,弗洛雷斯克里斯多博帕雷哈
论文集第13届年度会议上的创新和技术,在计算机科学教育,6月30日,2008年7月2日马德里,西班牙。
第2版
罗纳德L。格雷厄姆,唐纳德发送克努特,奥伦Patashnik混凝土数学Zeeshan阿姆贾德递归入门使用C:第1部分
 递归底漆使用C:第2部分
递归底漆使用C:第2部分
Zeeshan阿姆贾德
