DNA序列比对,利用动态规划算法
 {A}{S0的}介绍
{A}{S0的}介绍
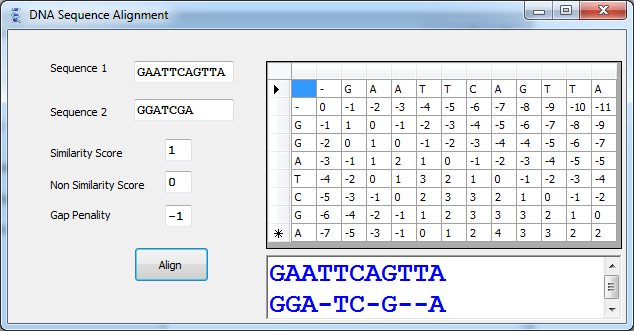
序列比对程序(成对排列)比较两个或多个(多个对齐)寻找一系列在所有序列中的顺序相同的字符序列。两个序列可以通过跨页写在两行排列。相同或相似的字符被放置在同一列,不相同的,可以被放置在相同的列不匹配,或对一个缺口( - )在其他序列。序列,以这种方式被认为是相似的。序列比对发现功能,结构和进化的生物序列信息非常有用。考虑以下DNA序列GACGGATTAG,和GATCGGAATAG。请注意,当我们将它们对齐高于其他:GA-CGGATTAG
GATCGGAATAG
唯一的区别是在上述序列的颜色标记。观察到的差距( - )在推出的第一个序列,让平等的基础完全一致。这篇文章的目的是提出一个高效的算法,需要两个序列,并确定它们之间的最佳路线。对齐的总得分取决于每个列的对齐。如果列有两个相同的字符,它会收到价值1(比赛)。不同的角色,将给该列的值-1(不匹配)。最后一列中的差距下降值-2(峡罚款)。最佳路线将是一个最大的总比分。上述路线将总比分:9×1×(-1)1×(-2)= 6。
这些参数匹配,不匹配和差距,最高刑罚可被调整到不同的价值观,根据选择序列或实验结果。
计算两个序列之间的相似性的方法之一是生成所有可能的路线和挑选最好的之一。然而,两个序列之间的路线是指数,这将导致innbsp;一个缓慢的算法,动态规划作为一种技术来产生更快的对准算法。动态规划尝试使用较小的情况下同样的问题已经计算的解决方案,以解决该问题的一个实例。给SEQ1和SEQ2两个序列,而不是决定作为一个整体的,动态的编程序列之间的相似性,试图建立的解决方案,以确定两个序列的任意前缀之间有相似之处。该算法用较短的前缀和开始使用以前计算的结果,更大的前缀来解决问题。
设M = SEQ1和N = SEQ2规模的大小,计算安排到(N-1)×(男1)数组项(J,I)包含SEQ2之间的相似性[1 ..... J] SEQ1 [1 .....我]。该算法计算值项(J,I),在短短三年以前的条目:{C}
{S}
(J,I)项的值可以由下列公式计算:{S2的} NBSP方程(1.1)
,其中p(J,I)= 1,如果SEQ2 [J] = SEQ1 [I](比赛分数)和P(J,I)= -1,如果SEQ2 [J] = SEQ1 [I]。
位于细胞对齐的得分(N-1,M-1)和算法的最大价值将追溯从细胞细胞(1,1)的第一项,生产所产生的对齐。如果单元格的值(J,I)已计算使用对角线细胞的价值,校准将包含的SEQ2 [J]和SEQ1 [I]。如果该值已使用上述细胞计算,校准将包含SEQ2 [J]和差距(' - ')在SEQ1 [I]。如果该值已使用左边的单元格计算,校准将包含SEQ1 [I]和差距在SEQ2(' - ')[J]。由此产生的对齐会产生完全穿越细胞(N-1,M-1),对初次进入细胞(1,1)。使用代码
我的代码有两个班,第一个名为DynamicProgramming.cs和第二名为Cell.cs.我将讨论在以下几行DynamicProgramming.cs类的细节,因为它描述了我的文章的主要思想。
第一类包含三个方法,描述了动态规划算法的步骤。第一种方法被命名为Intialization_Step,这种方法准备的矩阵A [I,J,持有任意前缀的两个序列之间的相似性。该算法用较短的前缀和开始使用以前计算的结果,更大的前缀来解决问题。public static Cell[,] Intialization_Step
(string Seq1, string Seq2,int Sim,int NonSimilar,int Gap)
{
int M = Seq1.Length;//Length+1//-AAA
int N = Seq2.Length;//Length+1//-AAA
Cell[,] Matrix = new Cell[N, M];
//Intialize the first Row With Gap Penalty Equal To i*Gap
for (int i = 0; i < Matrix.GetLength(1); i++)
{
Matrix[0, i] = new Cell(0, i, i*Gap);
}
//Intialize the first Column With Gap Penalty Equal To i*Gap
for (int i = 0; i < Matrix.GetLength(0); i++)
{
Matrix[i, 0] = new Cell(i, 0, i*Gap);
}
// Fill Matrix with each cell has a value result from method Get_Max
for (int j = 1; j < Matrix.GetLength(0); j++)
{
for (int i = 1; i < Matrix.GetLength(1); i++)
{
Matrix[j, i] = Get_Max(i, j, Seq1, Seq2, Matrix,Sim,NonSimilar,Gap);
}
}
return Matrix;
}
第二名为Get_Max方法计算公式1.1(J,I)的细胞的价值。{体C3}
第三种方法被命名为Traceback_Step。这种方法会产生穿越细胞矩阵(N-1,M-1),对初次进入细胞矩阵(1,1)对齐。{的C4}
在我的代码isnbsp名为Cell.cs.第二类;这个类操纵的基质细胞。每个单元有:一个位置表示由行和列的索引的索引一个是对齐的得分代表的价值[:对角线,以上和Leftquot;注意指针值quot]指针到以前的细胞,用于计算当前单元格的得分参考由若昂・塞图巴尔和Joao MEIDANIS quot;计算分子Biologyquot概论;